
Na Databázi národních autorit spouštíme automatickou aktualizaci, svatý grál Wikidat
Wikidata jsou pravděpodobně největším agregátorem českých databází vůbec. Databáze se ale neustále vyvíjí, mění a aktualizují. Jak to řešit? Nezbývá než jednou za čas stáhnout aktuální obraz databáze a provést synchronizaci. Jenže je to pracné, nudné a zbytečné. Daleko lepší je v pravidelných intervalech provést import automaticky. Právě to se nyní podařilo zařídit u Databáze národních autorit Národní knihovny ČR.
Automatické aktualizace jsou výzvou
Projekt vznikl za finanční podpory Národní knihovny, která dlouhodobě podporuje prohlubování „komunikace“ mezi jejich databázemi a Wikidaty. Největší a pro nás možná nejzajímavější databází je Báze národních autorit, která shromažďuje údaje o různých konceptech (osobách, místech, organizacích). Následně se tyto „štítky“ používají při popisování knih v dalších databázích, jako je Česká národní bibliografie.
O národních autoritách jsme psali již mnohokrát, ale veškeré naše snahy se zatím točily kolem jednorázových importů nebo ruční práce. Automatické aktualizace jsou složitější. Je potřeba vše perfektně ošetřit tak, aby nemyslící robot neudělal na Wikidatech chybu. A právě o to jsme se nyní pokusili.
Data, která přenášíme
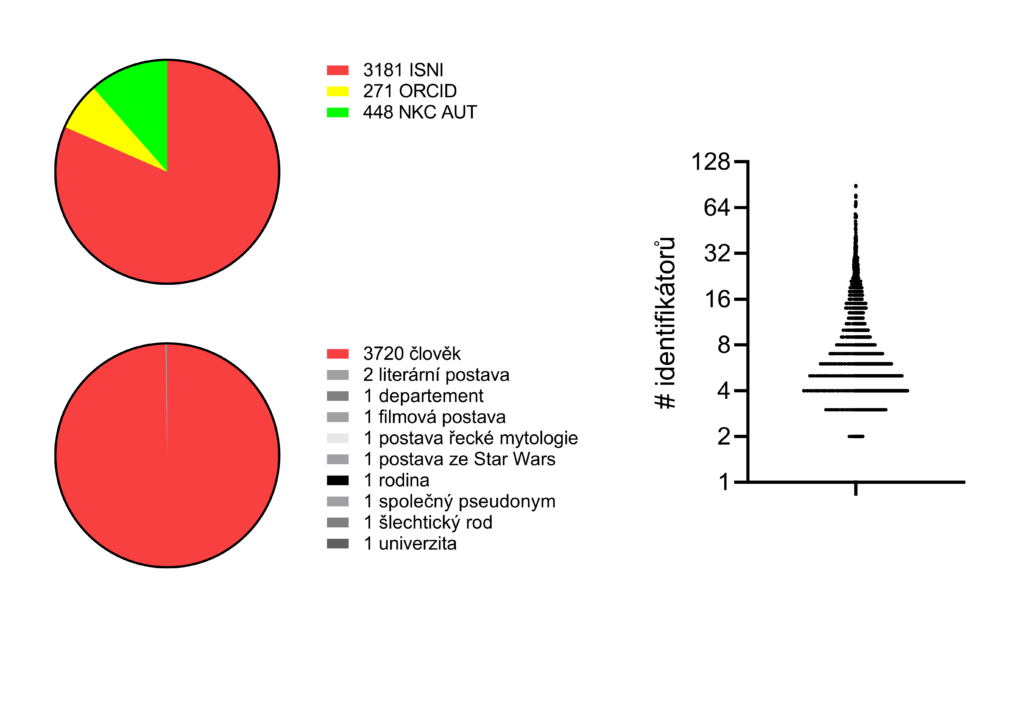
V rámci letošního projektu jsme se rozhodli zprovoznit pravidelnou aktualizaci odkazů na Wikidata a identifikátorů ORCID a ISNI, které knihovníci ručně přidávají do autoritních záznamů. Tyto odkazy jsou pro Wikidata velmi cenné, protože umožňují propojovat různé databáze a také vyhledávat a slučovat duplicity na Wikidatech. V neposlední řadě představují tyto odkazy cenná data pro uživatele Wikidat, třeba pro různé internetové databáze osob, které mohou vytvářet automatické odkazy na „související databáze“.
Data zatím cestují jen jedním směrem, tedy z národních autorit do Wikidat, takže se nejedná o synchronizaci v pravém slova smyslu. Nicméně ani na druhý směr nezapomínáme a poskytujeme Národní knihovně různá chybová hlášení, na základě nichž mohou svou databázi dále zkvalitňovat.
Jak je to řešeno technicky?
Národní knihovna publikuje svá opendata zejména ve formátu MARC XML. V pravidelných týdenních intervalech probíhá jejich aktualizace o nová data. Následně náš nástroj stáhne soubor a potřebné údaje z něj převede do tabulky, čili do formátu CSV. Tato tabulka je mimochodem veřejně k dispozici. Mezi tímto CSV a Wikidaty je následně poměrně složitá logika, v niž se vyhodnocuje, který údaj ještě ve Wikidatech není a měl by být vložen. A navíc, pokud ve Wikidatech hodnota sice je, ale je takzvaně „zavržena““”, k importu nepřistupujeme. Značí to totiž, že je s hodnotou něco v nepořádku.
Další technické detaily naleznete na GitHubu, kde je kód zveřejněn. Editace našeho robota na Wikidatech jsou označeny speciálním štítkem, takže je možné si je nechat vypsat. K 3. listopadu 2022 nástroj „vylepšil“ 3900 položek a další každý týden přibývají.
Výhled do budoucna
Tímto jsme završili letošní projekt spolupráce s Národní knihovnou, v rámci něhož jsme také připravovali skripty pro manuální extrakci různých „Wikidata-ready“ údajů z Báze národních autorit a používali je k naimportování několika desítek tisíc nových záznamů do Wikidat. Kromě jasných výstupů pro Wikidata je celá záležitost přínosem i pro Národní knihovnu. Ta se stává propojenější s Wikidaty, z nichž čerpá řadu údajů, ale také může využívat alternativní datový formát svých dat – CSV, které jsme v rámci projektu připravili.
V budoucnu plánujeme vybudovanou infrastrukturu dále využívat. Zmíněné CSV obsahuje celou řadu údajů z Národních autorit, jako jsou například místa narození a úmrtí, data narození a úmrtí, povolání a podobně. Po pečlivém zvážení a zavedení patřičné „automatické kontroly kvality“ by bylo možné i tyto údaje začít z Báze národních autorit přenášet automaticky každý týden do Wikidat.
Projekt je finančně podporován Národní knihovnou České republiky. Autory technického řešení jsou Vojtěch Dostál (User:Vojtěch Dostál) a Jiří Sedláček (User:Frettie).